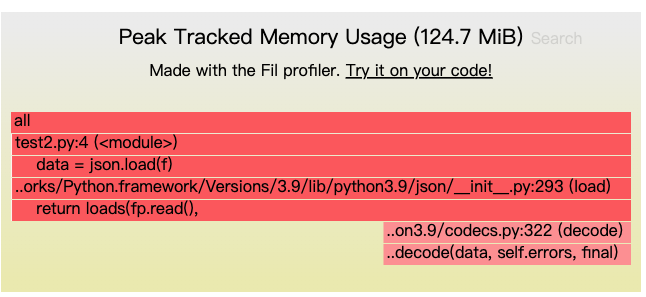
首先构造一个大的 JSON 文件,这里我们使用一个在 github上开源的一个 json 文件 large-file.json,文件大小为 24.9 M
文件内容大致如下:
1 2 3 4 5 6 7 8
[ {"id":"2489651045","type":"CreateEvent", "actor":{"id":665991,"login":"petroav","gravatar_id":"","url":"https://api.github.com/users/petroav","avatar_url":"https://avatars.githubusercontent.com/u/665991?"}, "repo":{"id":28688495,"name":"petroav/6.828","url":"https://api.github.com/repos/petroav/6.828"}, "payload":{"ref":"master","ref_type":"branch","master_branch":"master","description":"Solution to homework and assignments from MIT's 6.828 (Operating Systems Engineering). Done in my spare time.","pusher_type":"user"}, "public":true,"created_at":"2015-01-01T15:00:00Z"}, ... ]
withopen("large-file.json", "r") as f: data = json.load(f)
user_to_repos = {} for record in data: user = record["actor"]["login"] repo = record["repo"]["name"] if user notin user_to_repos: user_to_repos[user] = set() user_to_repos[user].add(repo)
withopen("large-file.json", "r") as f: for record in ijson.items(f, "item"): user = record["actor"]["login"] repo = record["repo"]["name"] if user notin user_to_repos: user_to_repos[user] = set() user_to_repos[user].add(repo)