>>> a = b = ["l","e","e","t","a","o"] >>> c = ["l","e","e","t","a","o"] >>> a is b # >>> a == b # >>> a is c # >>> a == c #
第二组的正确答案:
这个例子也不能理解,之前关于字符串池化的时候,也提过类似的例子,a,b 在同一行赋值, python 解释器进行了优化,将两者指向同一个对象,所以导致 a 和 b 值相等, id 也相等, 至于 a 和 c 很好理解,它们值相等,但是很明显,id值不一样.
3
1 2 3 4 5 6 7 8 9
>>> a = 256 >>> b = 256 >>> a is b # >>> a == b #
>>> c = 257 >>> d = 257 >>> c is d # >>> c == d #
第三组就更有意思了,答案:
这个例子,牵扯到另外一个知识点,关于 Integer 对象的一个小的知识点,让我们看一下官方原文:
The current implementation keeps an array of integer objects for all integers between -5 and 256, when you create an int in that range you actually just get back a reference to the existing object. So it should be possible to change the value of 1. I suspect the behaviour of Python in this case is undefined. :-)
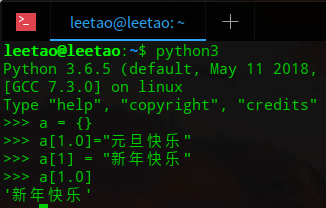
A dictionary’s keys are almost arbitrary values. Values that are not hashable, that is, values containing lists, dictionaries or other mutable types (that are compared by value rather than by object identity) may not be used as keys. Numeric types used for keys obey the normal rules for numeric comparison: if two numbers compare equal (such as 1 and 1.0) then they can be used interchangeably to index the same dictionary entry. (Note however, that since computers store floating-point numbers as approximations it is usually unwise to use them as dictionary keys.)
Numeric types used for keys obey the normal rules for numeric comparison: if two numbers compare equal (such as 1 and 1.0) then they can be used interchangeably to index the same dictionary entry.
from openpyxl import Workbook from openpyxl.compat importrange from openpyxl.utils import get_column_letter from openpyxl.worksheet.pagebreak import Break, PageBreak
wb = Workbook() ws = wb.active
for row inrange(1, 20): for col inrange(1,30): _ = ws.cell(column=col, row=row, value="{0}".format(get_column_letter(col)))
from openpyxl import Workbook from openpyxl.compat importrange from openpyxl.utils import get_column_letter from openpyxl.worksheet.pagebreak import Break, PageBreak
wb = Workbook() dest_filename = 'empty_book.xlsx'
ws = wb.active for row inrange(1, 20): for col inrange(1,30): _ = ws.cell(column=col, row=row, value="{0}".format(get_column_letter(col)))
Traceback (most recent call last): File "test.py", line 24, in <module> wb.save(filename = dest_filename) File "F:\workspace\python\test_openpyxl\test_openpyxl\lib\site-packages\openpyxl\workbook\workbook.py", line 391, in save save_workbook(self, filename) File "F:\workspace\python\test_openpyxl\test_openpyxl\lib\site-packages\openpyxl\writer\excel.py", line 284, in save_workbook writer.save(filename) File "F:\workspace\python\test_openpyxl\test_openpyxl\lib\site-packages\openpyxl\writer\excel.py", line 266, in save self.write_data() File "F:\workspace\python\test_openpyxl\test_openpyxl\lib\site-packages\openpyxl\writer\excel.py", line 83, in write_data self._write_worksheets() File "F:\workspace\python\test_openpyxl\test_openpyxl\lib\site-packages\openpyxl\writer\excel.py", line 203, in _write_worksheets xml = ws._write() File "F:\workspace\python\test_openpyxl\test_openpyxl\lib\site-packages\openpyxl\worksheet\worksheet.py", line 893, in _write return write_worksheet(self) File "F:\workspace\python\test_openpyxl\test_openpyxl\lib\site-packages\openpyxl\writer\worksheet.py", line 151, in write_worksheet xf.write(ws.page_breaks.to_tree()) AttributeError: 'list' object has no attribute 'to_tree'
# worksheet.py # 省略部分代码 if ws.page_breaks: ifisinstance(ws.page_breaks,list): for page_break_item in ws.page_breaks: xf.write(page_break_item.to_tree()) else: xf.write(ws.page_breaks.to_tree())